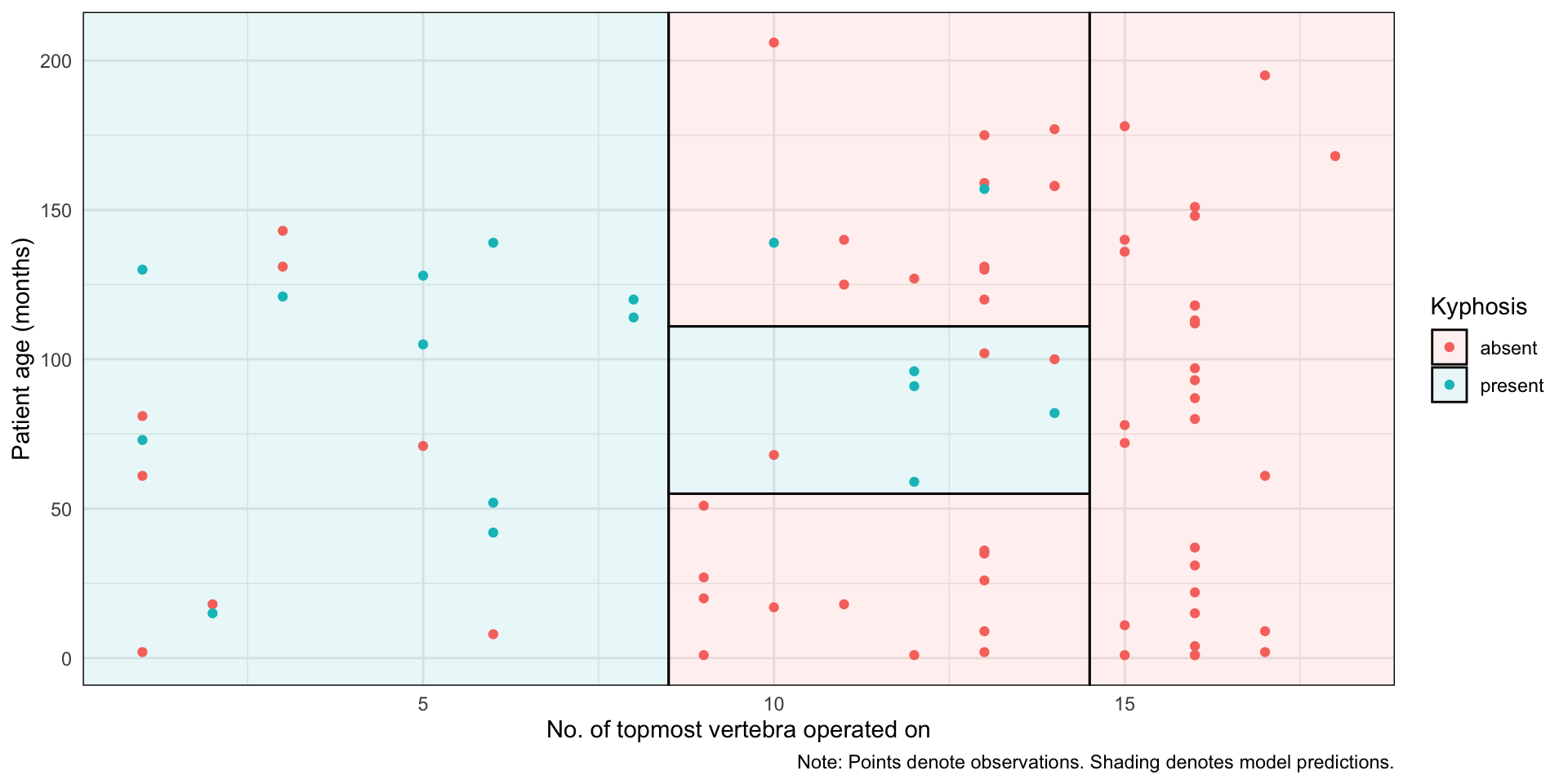
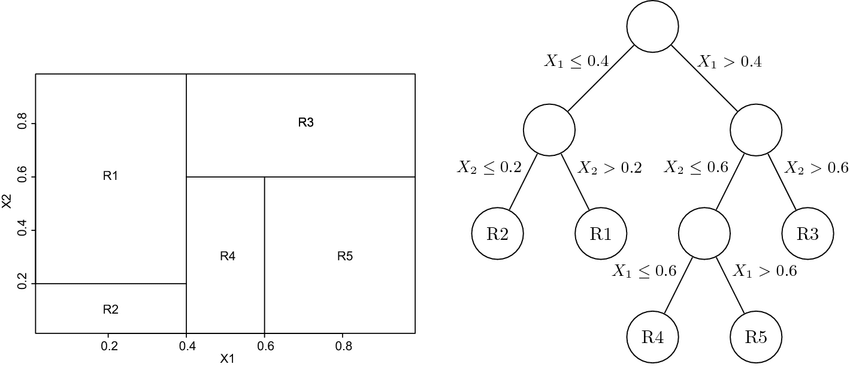
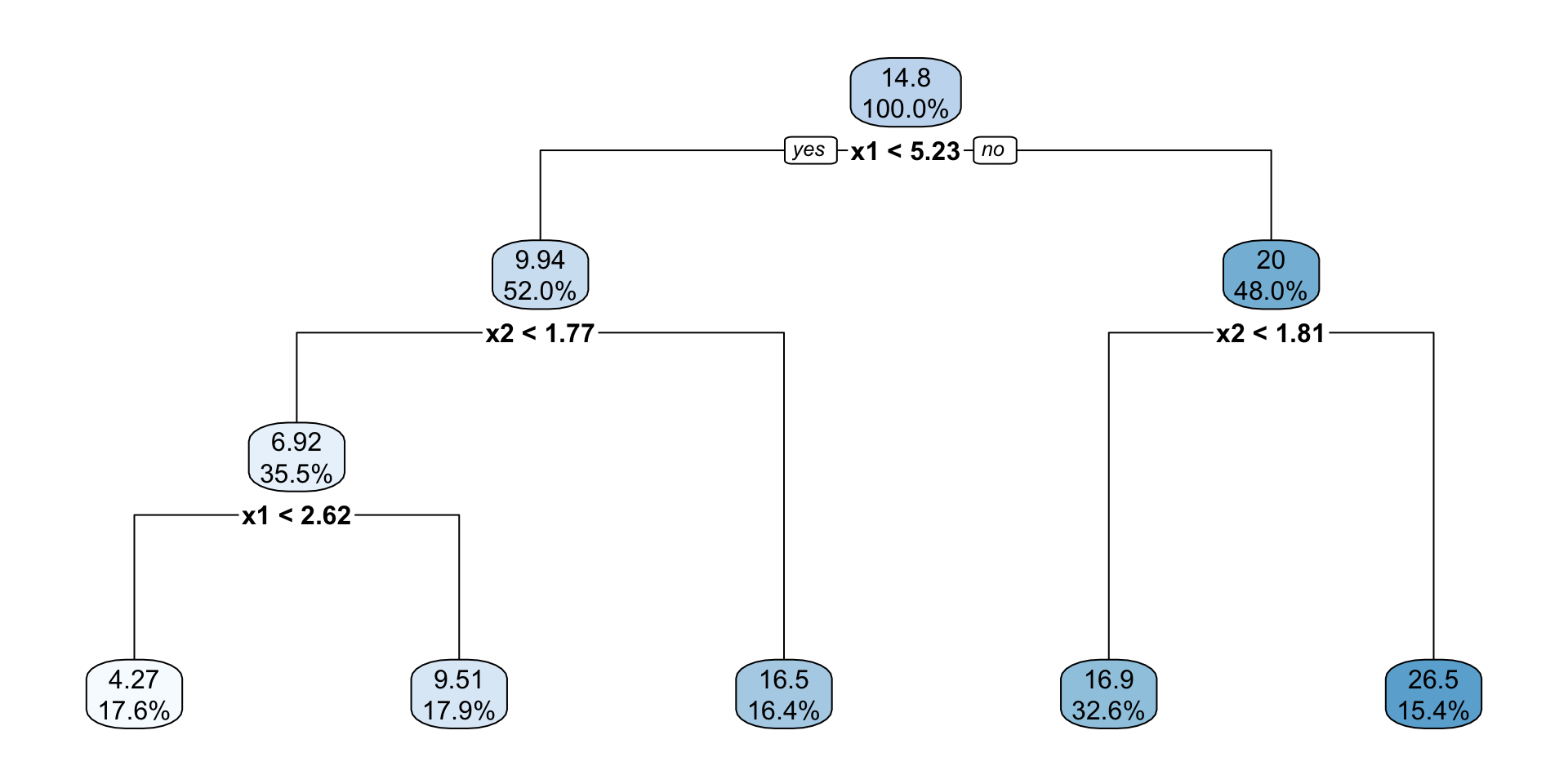
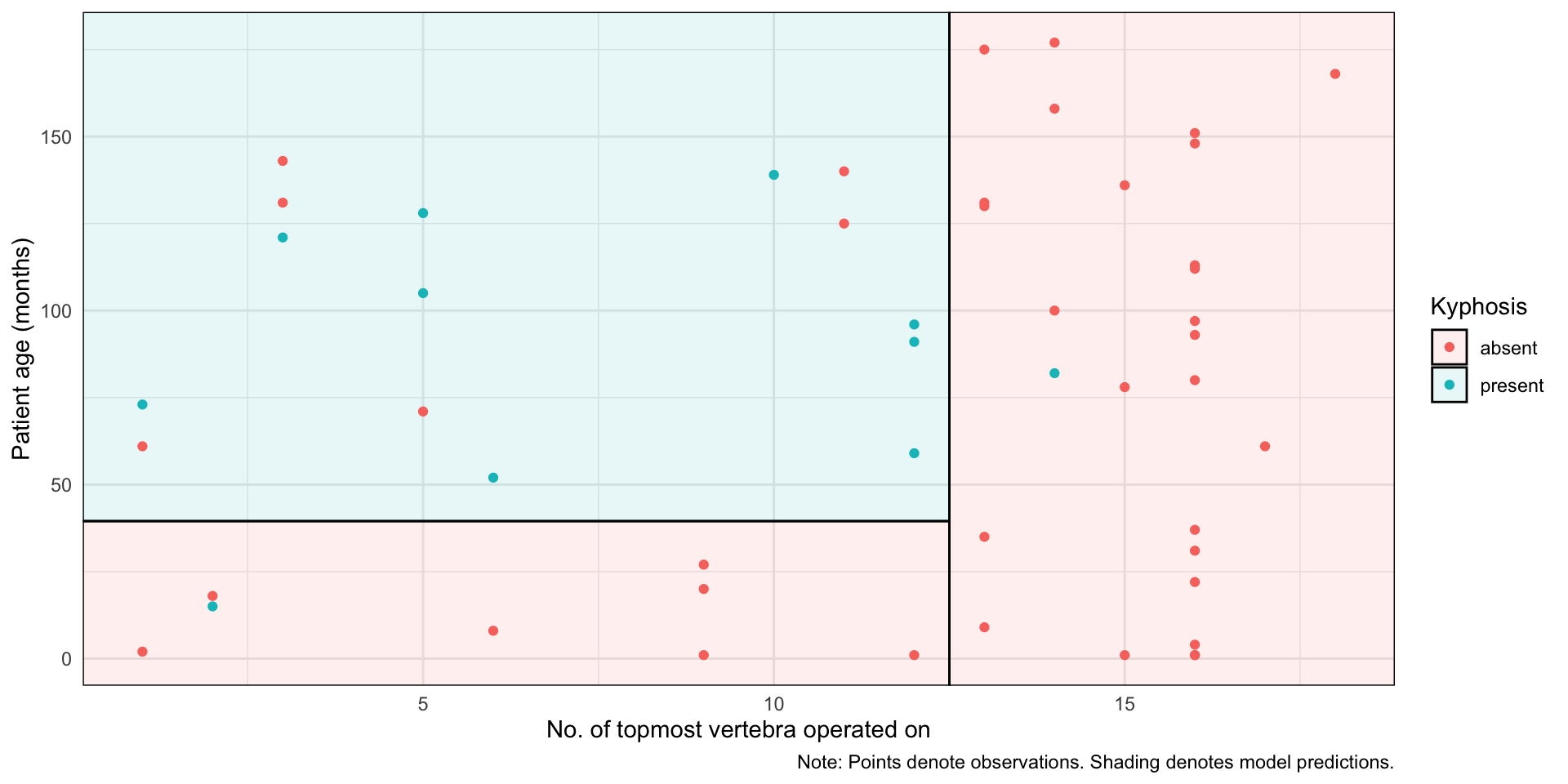
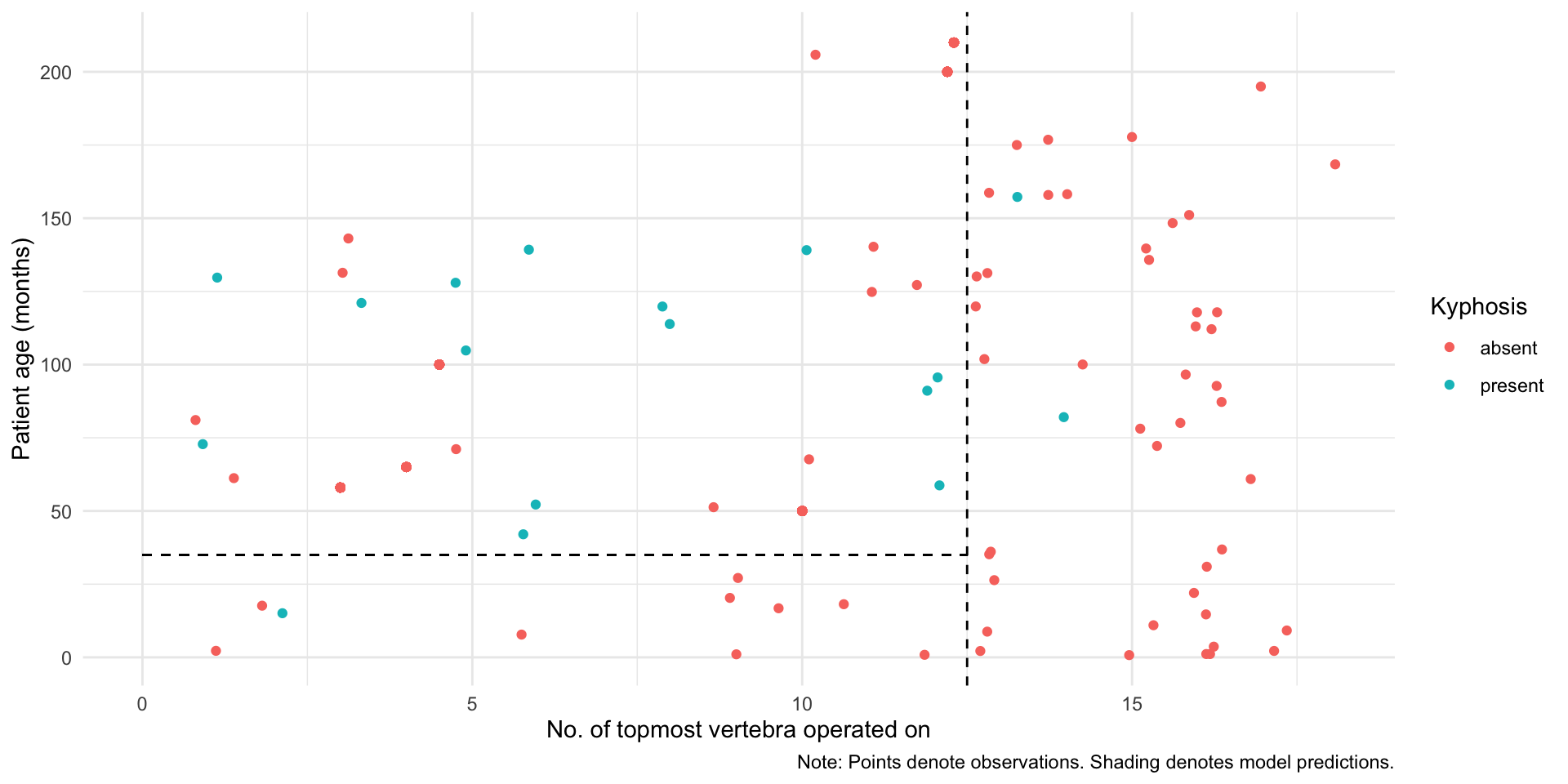
Classification and Regression Trees recursively divide the covariate space into two so that MSE decreases each time we add a partition. In the figure below, we have a partition with 5 leaves.
Code
# See the full code at Grant Mcdermott's repositorylibrary(rpart) library(parsnip)library(tidyverse)library(parttree)set.seed(123) ## For consistent jitterfit =rpart(Kyphosis ~ Start + Age, data = kyphosis)ggplot(kyphosis, aes(x = Start, y = Age)) +geom_parttree(data = fit, alpha =0.1, aes(fill = Kyphosis)) +# <-- key layergeom_point(aes(col = Kyphosis)) +labs(x ="No. of topmost vertebra operated on", y ="Patient age (months)",caption ="Note: Points denote observations. Shading denotes model predictions." ) +theme_minimal()
Steps
Choose X_1 or X_2.
Choose the cutoff for dividing.
Repeat these steps.
Trees recursively partition the covariate space so that MSE decreases each time we add a partition.
Figure from Beaulac and Rosenthal(2019)
For regression trees, the criterion for choosing covariate and a cutoff pair is the MSE.
Split the data into S^{tr}(training) and S^{te}(test).
Within S^{tr}, choose X_i and a cutoff k that minimizes MSE:
The resulting MSE of the model given a data S and partition \Pi would be
MSE_\mu(S, S^{tr}, \Pi) = \frac{1}{\#(S)} \sum_{i \in S} \biggl[Y_i -\hat{\mu}(X_i; S^{tr}, \Pi)\biggr]^2
In this paper, we use the adjusted MSE:
MSE_\mu(S, S^{tr}, \Pi) = \frac{1}{\#(S)} \sum_{i \in S} \biggl[(Y_i -\hat{\mu}(X_i; S^{tr}, \Pi))^2- {\color{blue}Y_i^2}\biggr]
which does not affect the splitting mechanism but makes the algebra more interpretable.
S^{est} to estimate CATEs and take no role in building a tree
How does this change the tree?
For outcome prediction(Y) - Joonwoo
For CATE(\tau(X)) - Jeongwoo
Simulation Results - Minseo
Honest Inference for Outcome Averages
Notations for predicted outcomes
Given a partition \Pi, conditional mean is given by: \begin{equation*}
\mu(x;\Pi) = \mathbb{E}\left[Y_i | X_i \in \textit{l}(x;\Pi)\right]
\end{equation*}
Given a sample \mathcal{S} we estimate conditional mean is given by \begin{equation*}
\hat{\mu}(x;\mathcal{S},\Pi) = \frac{1}{\#(i \in \mathcal{S} : X_i \in \textit{l}(x;\Pi))}\sum\limits_{i \in \mathcal{S}:X_i \in \textit{l}(x;\Pi)}Y_i
\end{equation*}
Limitations of CART
We cannot simply use CART to estimate HTE.
Potential bias in the leaf estimates
does not consider variance in tree splitting
Limitations of CART
Suppose Y_i \in \mathbb{R}, \quad X_i \in \{L,R\}
Only two possible partitions : \begin{equation*}
\Pi = \begin{cases}
\{L,R\} & (\text{no split}) \\
\{ \{L\}, \{R\} \} & (\text{split})
\end{cases}
\end{equation*}
The second term penalizes a partition that increases variance in leaf estimates (e.g. small leaves) \begin{align*}
-\hat{\mathbb{V}}_{\mathcal{S}^{est},X_i}[\hat{\tau}(X_i;\mathcal{S}^{est},\Pi)]
= -\frac{2}{\text{N}^{\text{tr}}}\sum_{\ell \in \Pi}(\frac{S^2_{\mathcal{S}^\text{tr}_\text{treat}}(\ell)}{p}+\frac{S^2_{\mathcal{S}^\text{tr}_\text{control}}(\ell)}{1-p})
\end{align*}
Pros and Cons of Honest
Pro:
Honest target not only removes potential bias in leaf estimates but also penalizes high variance
Cons: NO reward for heterogeneity of treatment effects
(c.f. \sum\hat{\tau}^2 term in Causal Tree MSE)
Alternative Methods for Constructing Trees
(2) Squared T-statistic Trees (TS)
Su et al., (2009)
Split Rule: split if ({\color{red}\overline{\tau}_L-\overline{\tau}_R})^2 is sufficiently large
similar to two-sample t test
\begin{align*}
T^2 \equiv N \cdot
\frac{({\color{red}\overline{\tau}_L-\overline{\tau}_R})^2}{S^2/N_L+S^2/N_R}
\end{align*} where S^2 is the conditional sample variance given the split
Pros: (only) rewards for heterogeneity of treatment effects
Cons: no value on splits that improve the fit(c.f. Fit-based Trees)
Simulation Study: Set-up
Goal: Compare the performance of proposed algorithms (Adaptive vs. Honest)
Shallower tree (\because smaller leaves \rightarrow higher \mathbb{V})
Smaller # of samples \rightarrow Less personalized predictions and lower MSE
Benefit
EASY
Holding tree from \mathcal{S}^{\color{red}tr} fixed, can use standard methods to conduct inference (confidence interval) within each leaf of the tree on \mathcal{S}^{\color{red}te}
(Disregard of the dimension of covariates)
No assumption on sparsity needed (c.f. nonparametric methods)
vs Dishonest with double the sample
Honest does worse if true model is sparse (also the case where bias is less severe)
Dishonest has similar or better MSE in many cases, but poor coverage of confidence intervals
Use different method (e.g. Radom Forest) to provide a more personalized estimation. Causal Tree is to answer questions on the relation between covariates and how they interplay with treatment effects.
Is smaller number of samples bad?
Again, we’ve moved the goal post here. We are not trying to give the best prediction of effect on individuals. Rather, recursive partitioning assists figuring a general relation between covariates and treatment effects.
Why 50:50 in sample splitting?
Sample ratio could be taken differently in different problems and data available.
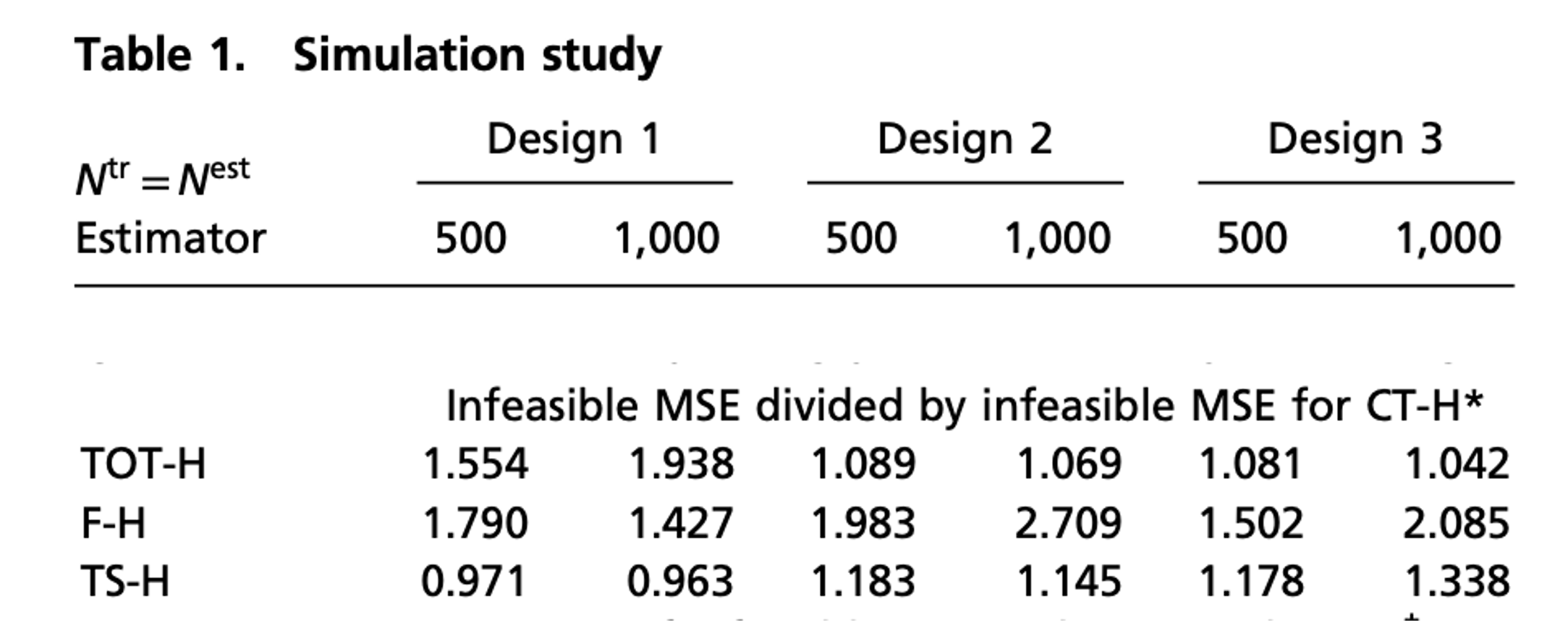
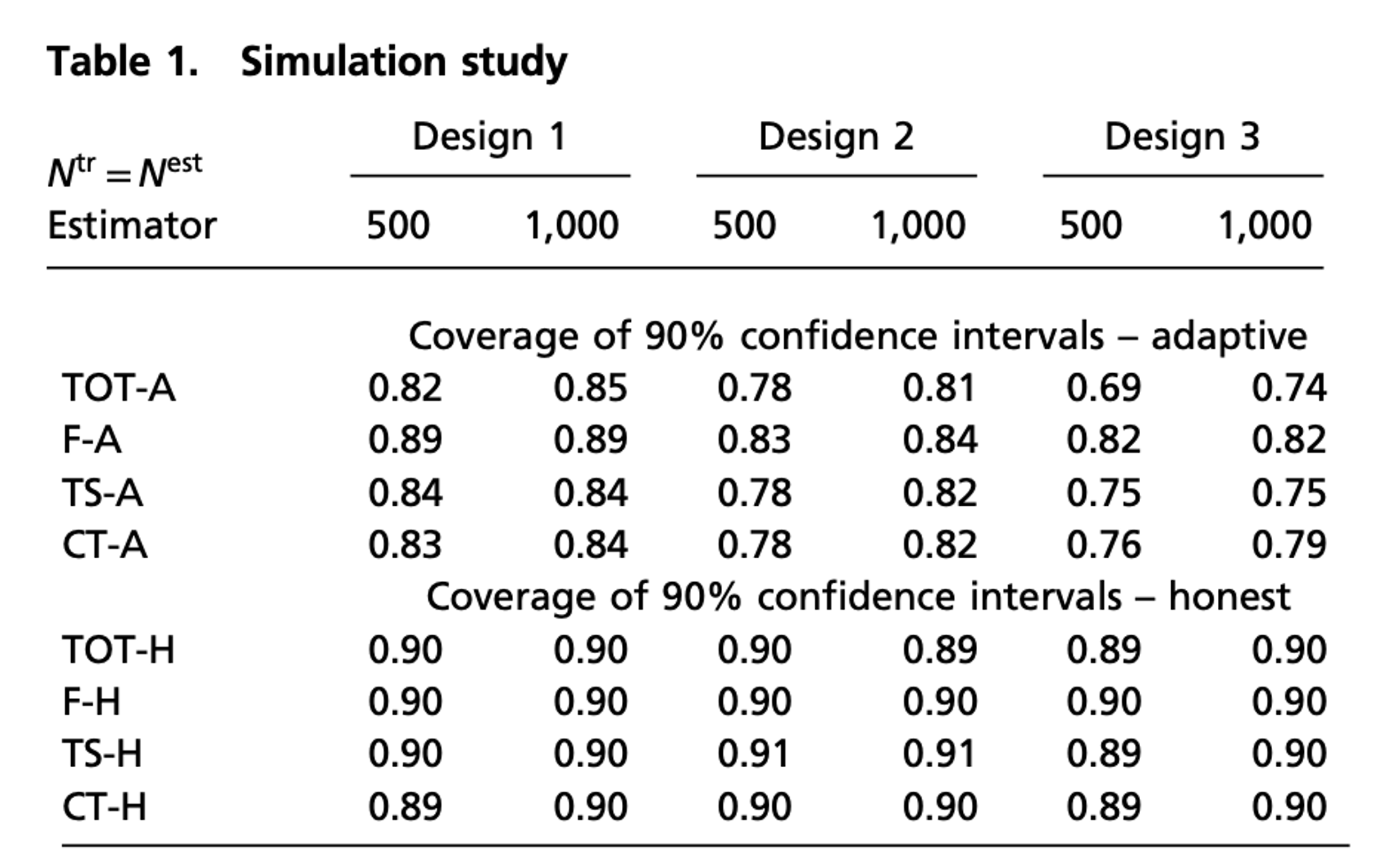
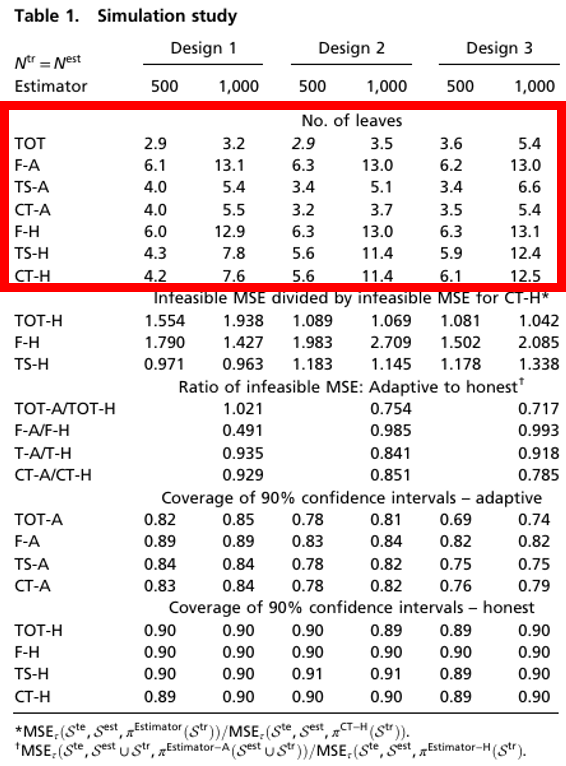
Simulation Study: Results
Number of Leaves(Tree Depth)
CT-H:
Splitting criteria: Maximizes – MSE
F-H:
Splitting criteria: Maximizes outcome prediction
Build deeper trees than that of CT
Less prone to overfitting on treatment effects
TS-H:
Splitting criteria: Maximizes squared t-statistic
Tree depth similar to that of CT
Adaptive versions still prone to overfitting
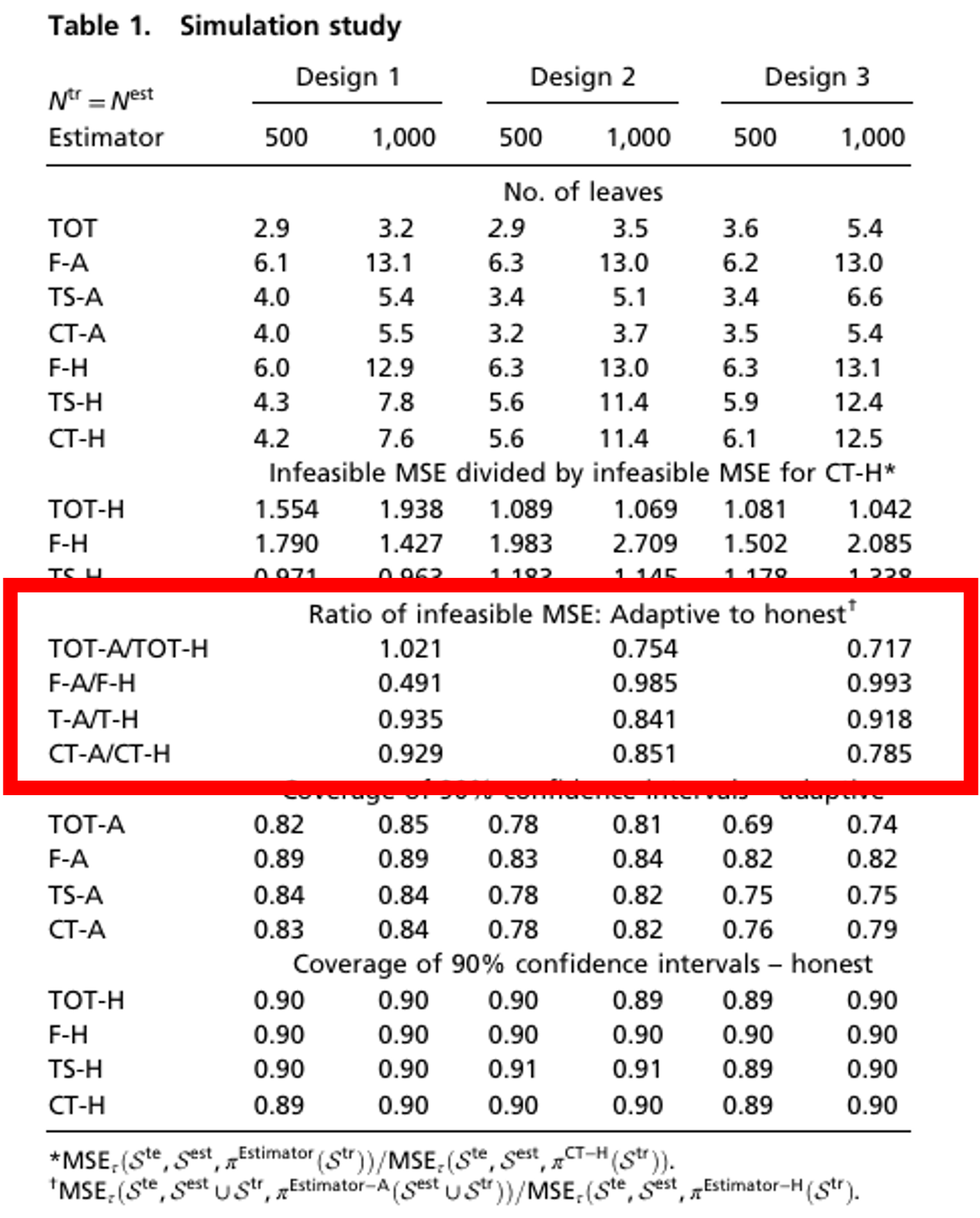
Simulation Study: Results
Adaptive vs Honest : Ratio of infeasible MSE
Honest estimation shows higher MSE in most cases \rightarrow Uses only half the data, leading to lower precision
Fit estimator performs poorly in Design 1 \rightarrow With smaller sample size, it tends to ignore treatment heterogeneity
As design complexity increases, the MSE ratio decreases. \rightarrow Adaptive estimators overfit more in complex settings.